Distributed Computing is offered in collaboration with Parallel Works.
Parallel Works is a company that delivers supercomputing as a service with the goal of speeding up the calculation process and also running multiple types of analyses simultaneously.
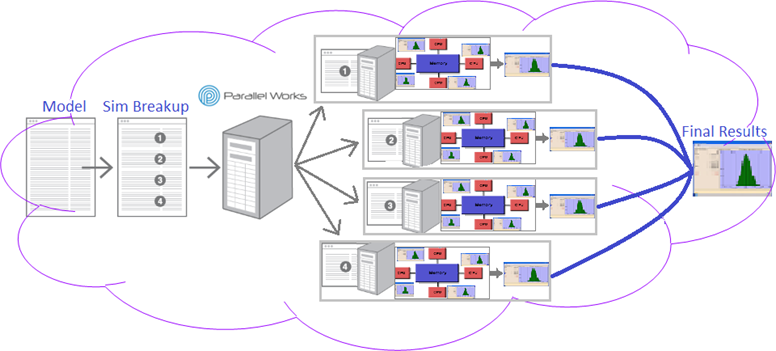
The analysis is 'split' into multiple batch files which then are run on multiple computers (on the cloud). At the end the results are merged and returned to the user as one file.
Parallel Works offers Distributed Computing with Shared Memory, thus multiple analyses can be performed simultaneously and on as many computers as needed in a very short time.
Parallel Works can be accessed at https://go.parallel.works/u/
== GETTING STARTED ==
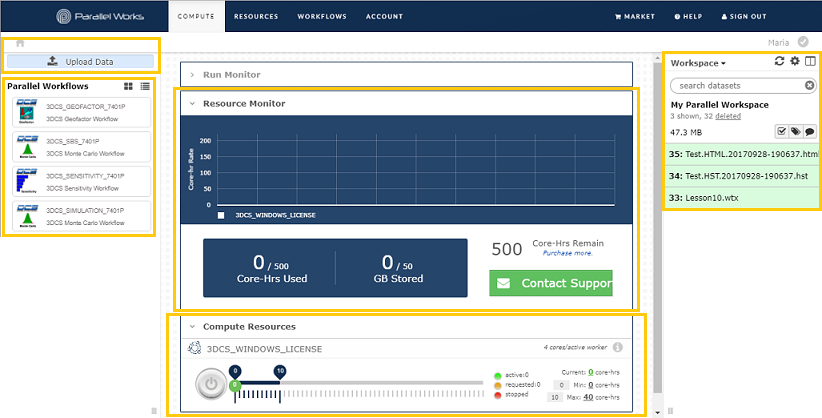
The COMPUTE interface is your primary activity monitor on the Parallel Works platform. Select applications, adjust resource requirements and view past run results from this page.
oParallel Workflows - On the left side of the interface you will find your selected parallel workflows (Monte Carlo analysis, Contributor Analysis, GeoFactor Equation-Based, etc). Click these icons to access the workflow execution interface.
oUpload Data - Manipulate the input files for your workflow.
oResource Monitor - Track the usage of your compute resources.
oCompute Resources - Your “Supercomputer in a box.” Indicate scaling preferences and monitor resources activity. Click the power button to launch your parallel cluster.
HINT: To edit your resource, turn OFF your resource via the power button. Make desired edits and then click the power button again to turn on so that the edits will update properly.
oWorkspace - Save and manage your workflow input and output files.
== KEY PAGES ==
![]()
oCOMPUTE - The compute interface is the primary control panel for setting and monitoring your parallel compute resources. Upload input files and select parallel tools to run, see current workspace files and adjust compute resources.
oRESOURCES - Under Resources, you can design and prepare your parallel computing resources. Set up new compute resource types and select desired cloud instance preferences.
oWORKFLOWS - Build encapsulated workflows with the Workflows interface. Upload existing scripts or code directly in the built in IDE (Integrated Development Environment). Define inputs and outputs, and see a preview of the workflow tool execution widget.
oACCOUNT - Manage your account details and purchase Parallel Compute Packs here.
oMARKET - Search and select pre-built workflows and templates from Parallel Works and other solution partners.
==USING PARALLEL WORKS==
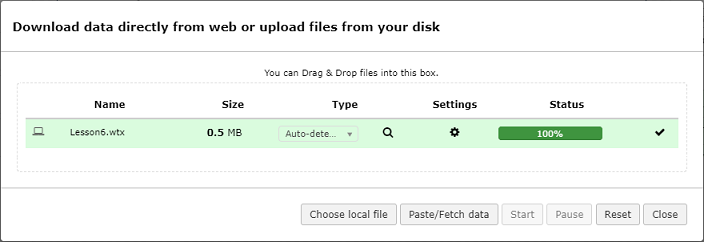
1. From COMPUTE select Upload Data; you can Drag & Drop files or Choose local file. Press Start to upload data.
1. START RESOURCES
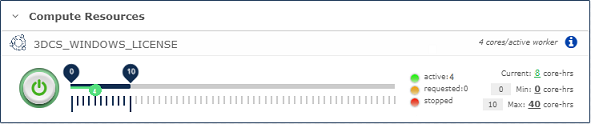
To run a workflow you need to start the resources. The Compute Resources are shown on the COMPUTE page. Push the power button to toggle between On/Off. The upper blue bar is maximum number of worker nodes. The lower green bar is current in use workers (yellow when starting up).
1A) RUN SIMULATION
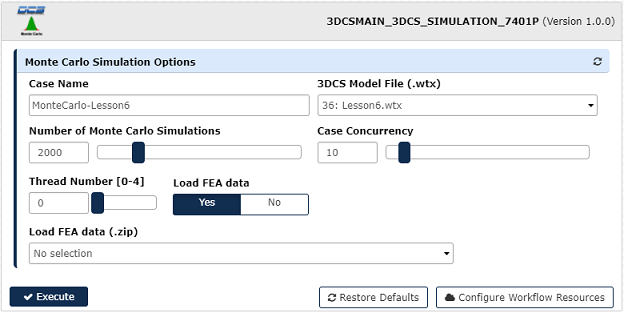
Select the 3DCS_SIMULATION_7401P workflow and fill out the form. To run the workflow press Execute.
oCase Name - Name the simulation run. The results are formatted as {Case Name}.hst.{time}.hst
o3DCS Model File (.wtx) - All uploaded wtx files are listed and can be selected from the drop-down.
oNumber of Monte Carlo Simulations - Input the number of simulations to run.
oCase Concurrency - Input the number of workers to run the simulation.
oLoad FEA data - Select Yes if the model requires FEA data to run.
oLoad FEA data (.zip) - Select the zip file containing the FEA data needed.
oExecute - Run the workflow.
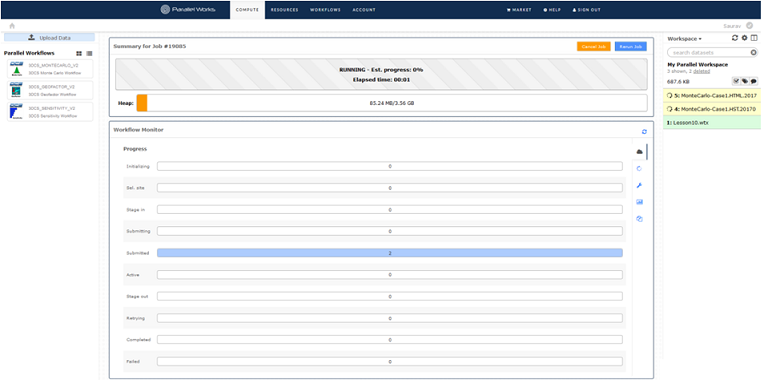
oWorkflow Monitor - When you execute the workflow it will load the Monitor page. You can monitor the progress of the job.
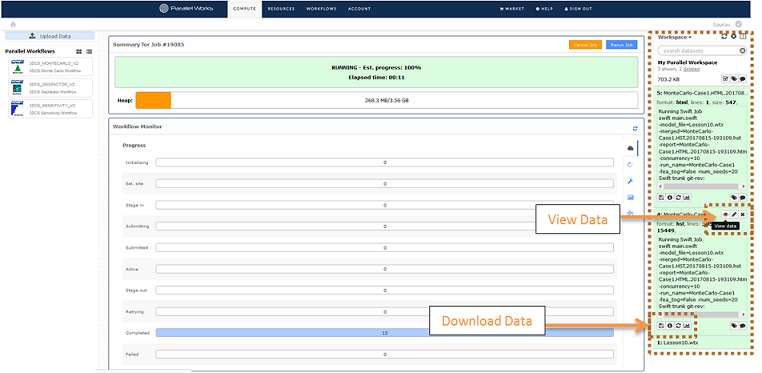
oResults - When the job is finished you can view or download the results. The results are raw data (hst) and an HTML report.
1B) RUN Contributor Analysis
oSelect the 3DCS_SENSITIVITY_7401P workflow and fill out the form. To run the workflow press Execute.
oCase Name - Name the sensitivity run. The results are formatted as {Case Name}.hlm.{time}.hlm
o3DCS Model File (.wtx) - Select the model file.
oCase Concurrency - Input the number of workers to run the sensitivity, less than or equal to the number of Contributors.
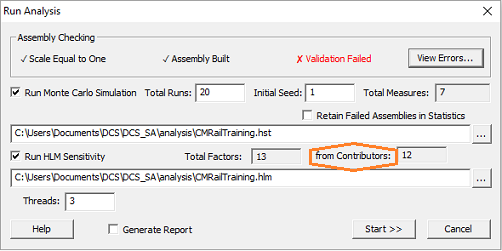
oLoad FEA Data - Select Yes if the model requires FEA dara to run.
oLoad FEA data (.zip) - Select the zip file containing the FEA data needed.
oExecute - Run the workflow
1C) RUN GEO FACTOR - GeoFactor is no longer supported and will no longer be updated (starting from 7.6.0.1).
oSelect the 3DCS_GEOFACTOR_7401P workflow and fill out the form. To run the workflow press Execute.
oCase Name - Name the Geo Factor run. The results are formatted as {Case Name}.gf2.{time}.gf2
o3DCS Model File (.wtx) - Select the model file.
oCase Concurrency - Input the number of workers to run the geofactor, less than or equal to the number of Contributors.
oLoad FEA data - Select Yes if the model requires FEA data to run.
oLoad FEA data (.zip) - Select the zip file containing the FEA data needed.
oExecute - Run the workflow.
==METHODOLOGY==
Parallel Works uses the open source language swift to generate workflows. DCS workflows utilize the Batch Processor (SimuMacro) from the Multi-CAD engine to run in parallel. The entire process is illustrated below.
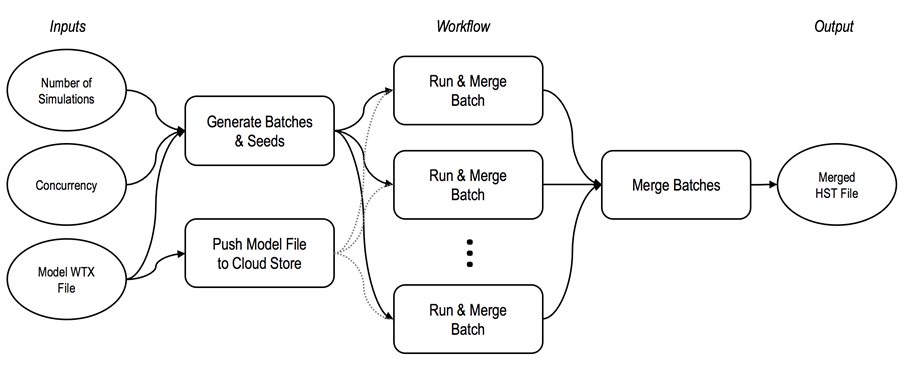
oInputs - Inputs are from the workflow form.
oGenerate Seeds - Uses a python script to generate random seed for each worker (only for simulation).
oPush Model - Push the model (and FEA data) to cloud storage for quick access from each worker.
oRun - This step runs SimuMacro on each worker to compute. First a working directory is created and a script file is generated. The script file uses the inputs to distribute the job across available workers. The model file (and FEA data) is downloaded from the cloud storage to the working directory. Results are pushed to the cloud storage.
oMerge - Uses one worker to merge all results into one file. Gets result files from cloud storage. Generates script file and runs SimuMacro to merge. This step also generates an HTML report with the available results. The final results file and HTML report are uploaded to cloud storage. These files can then be easily downloaded onto a personal computer to visualize the HTML report or load the Raw data (hst, hlm, gf2) files into the 3DCS software.